Most AI patent writing gets weak right where it matters most: the moment your model leaves training and starts doing real work in the world. That is where value shows up. It is also where copycats often try to sneak around what you built. If your invention does something new during inference, or if your deployment setup makes the system faster, safer, cheaper, more reliable, or easier to scale, your claims should say that clearly. Not in vague research language. Not in broad buzzwords. In plain, sharp terms that track what the system actually does when it is live.
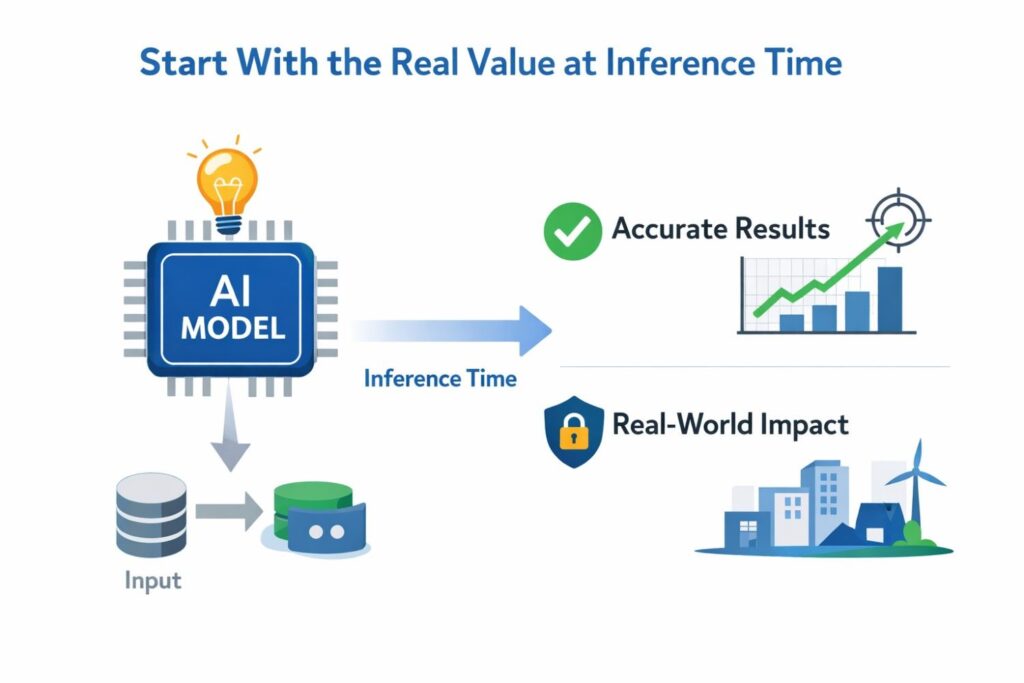
Start With the Real Value at Inference Time
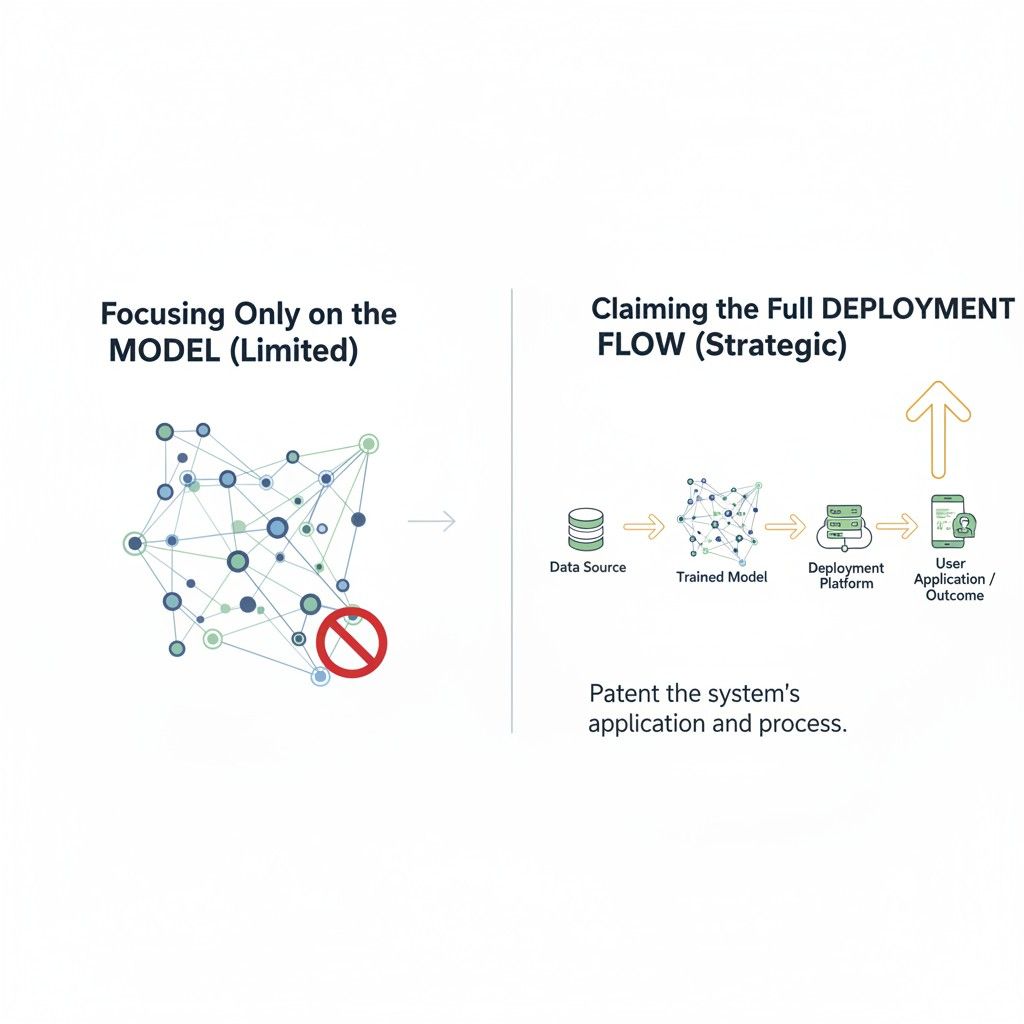
When most teams think about patent claims for AI, they start with the model itself. They focus on architecture, training data, model weights, or benchmark scores.
That feels natural, but it often misses the part of the system that creates the most business value.
In many real products, the value does not come from training alone. It comes from what happens when the system is live, taking inputs, making decisions, and producing outputs that affect users, machines, workflows, and revenue.
If you want stronger claims, you need to begin where the product earns its keep. That means looking closely at inference time.
This is where your system handles real requests, adapts to conditions, manages cost, controls latency, protects safety, and turns raw model output into something useful enough to ship.
That is also where competitors often copy what works while changing just enough under the hood to argue they did something different. A smart claim strategy starts by locking onto the practical value created during this live stage.
Why inference is often where the money is made
A patent should protect what matters in the real world, not just what looks good in a research paper. For many companies, inference is where the business case becomes real.
It is the point where the system serves customers, powers product features, and creates a repeatable edge.
A business may have a fine-tuned model, but the true advantage may come from how that model is used in production to handle speed, reliability, routing, filtering, orchestration, fallback logic, or output control.
This matters because many AI products are not won by the team with the fanciest model. They are won by the team that gets dependable output at the right cost and speed while keeping the user experience smooth.
If your patent claims stop at general model behavior, you may leave the most valuable part exposed. If your claims capture how the system behaves during live use, you start protecting the part that customers actually feel.
The patent should follow the product, not the lab demo
Founders and technical teams often explain their invention in the order they built it. They begin with data collection, then training, then evaluation. But a claim does not need to follow that path.
A good claim follows value. It should track the part of the system that delivers a business result that others will want to copy.
That shift changes the whole drafting process. Instead of asking, “What is special about our model?” ask, “What is special about how our product performs when a real request comes in?”
That simple change can reveal much stronger claim material. You may find that the most defensible point is not the model type at all.
It may be the way the system selects context, allocates compute, chooses a serving path, validates output, or triggers an action only when confidence passes a threshold tied to downstream risk.
Inference is where design choices become business assets
Many teams treat serving logic as engineering detail. That is a mistake. In a strong patent strategy, those choices may be central assets.
The way you handle inference can shape cost of goods, response time, user trust, uptime, and margins. Those are not side issues. Those are business outcomes.
If your system does something smart during inference that leads to a better business result, that deserves close attention. Maybe your platform routes easy requests to a lighter model and harder ones to a deeper system.
Maybe it only calls a retrieval step when certain input traits are present. Maybe it compresses or restructures incoming data before inference in a way that cuts cost without hurting accuracy.
These are not just technical moves. They may be the exact reason your product works at scale.
A weak claim talks about prediction in general terms
Claims become fragile when they describe inference as if all models work the same way. Saying that a system receives an input and generates an output is too loose.
That kind of language may sound broad, but it often protects very little because it does not capture what is truly different about your implementation.
The better path is to describe the live decision flow with care. What triggers a step? What is evaluated? What gets selected, skipped, constrained, transformed, or verified?
What result does that create in production? The more your claim reflects real operating logic, the harder it becomes for someone else to copy your method without stepping into your claim scope.
A strong claim connects live behavior to a concrete result
The strongest inference claims often tie actions to outcomes. That does not mean stuffing the claim with every metric you have.
It means showing how the system behaves in a way that drives a practical result. The claim should not read like a slogan. It should read like a mechanism.
For example, instead of saying the model improves response quality, think about what actually happens. Does the system select among multiple inference paths based on a property of the input?
Does it apply a safety layer before an action is taken? Does it produce a ranked output and then pass only a subset into a control layer that chooses a next step? These details make the invention legible.
They also make it much easier to argue that the system is doing something real and specific.
Start with the moment a request arrives
A useful way to draft this section is to begin at the first live event. A user asks a question. A sensor sends a signal.
A software client submits a prompt. A device requests a classification. That moment is the gateway into your claim story.
Once you start there, you can map the exact path your system follows. Many teams discover value in this sequence. The request may be normalized, filtered, enriched, split into parts, or checked for certain traits.
Each of those steps may affect which model is used, what context is attached, which policy layer is triggered, or whether the system returns a result at all. If those choices shape business performance, they may deserve claim coverage.
Look for hidden invention in pre-inference handling
Some of the most useful claim material lives right before inference begins. Teams often overlook this because it feels too ordinary. But what happens just before the model runs can be where a major advantage sits.
Suppose your system rewrites an incoming request into a structured form that makes downstream inference more stable. Suppose it removes noisy fields from machine data before classification.
Suppose it tags an incoming task by urgency, domain, or risk level and uses that tag to control the serving path. These steps can define how well the system performs in the wild.
When they matter to output quality, speed, cost, or trust, they should not be buried in the spec as minor details. They should be explored as possible claim anchors.
Find the business reason the step exists
One simple drafting habit can sharpen your claims fast. For each step in your inference flow, ask why it exists. Not why it exists in code, but why it exists for the business.
Does it reduce cost? Speed up results? Improve consistency? Lower false alarms? Prevent harmful outputs? Support a premium feature? Make the system usable in a regulated setting?
When you answer that question clearly, you start seeing which parts deserve claim focus. A step that saves a few lines of code may not matter. A step that cuts serving cost enough to make the product viable absolutely matters.
A step that keeps an automation tool from taking unsafe action matters even more. Patent claims should follow these business-critical choices.
Use product metrics to spot claim-worthy behavior
Your product dashboard may be more useful for patent drafting than your model card.
Teams already track latency, failure rates, conversion, retention, escalation rates, compute spend, and user drop-off. Those numbers point to what the system is doing that matters.
If one serving method gives a major cost drop without harming output quality, study that flow. If one output control method reduces user corrections, study that. If one routing layer lets enterprise customers trust the system enough to expand usage, that may be the heart of the invention.
Patent strategy gets sharper when it follows the mechanics behind business metrics instead of abstract model talk.
Claims should protect the winning workflow
A business does not win because a model exists. It wins because the product repeatedly solves a problem in a way customers prefer. That usually means the full inference workflow matters more than any one isolated step.
A strong section on inference should therefore describe the workflow as the user experiences it, while still showing the hidden logic that makes the experience possible.
This gives you room to claim the path itself.
The value may lie in the sequence of receiving an input, evaluating a condition, selecting a model class, applying a control rule, generating an intermediate result, validating it, and then issuing a final output or action.
That is far more protectable than a claim that merely says a trained model makes a prediction.
Think about what a copycat would actually copy
This is one of the best practical tests. Imagine a fast-moving competitor trying to recreate your product after seeing it work. What would they copy first? They would not begin with your slide deck.
They would begin with the live system behavior that makes the product effective and affordable.
That means your drafting should focus on the serving tricks, routing rules, context logic, quality checks, output guards, and action thresholds that create your edge.
These are often the exact places a copycat tries to imitate while changing labels and internal structure. If you write claims around those real choices, you raise the cost of imitation.
Separate novelty from technical decoration
Not every detail belongs in a claim. Some parts of an inference pipeline are just there because every serious system needs them. The trick is knowing which steps are basic plumbing and which steps create the edge.
A good way to test this is to imagine deleting a step. If the system still delivers roughly the same business value, that step may not be central.
But if removing the step causes latency to spike, safety to drop, cost to rise, or output quality to collapse in real use, then you may be looking at claim-worthy substance.
This helps keep your claims focused on what is essential rather than cluttered with extra detail.
Draft around decisions, not labels
Many weak AI claims lean too hard on names. They name a model type, a pipeline class, or a serving pattern, and then assume that label does the work. It does not.
Good claims describe decisions and operations. They explain what the system does under what condition and why that changes the result.
This matters because labels are easy to design around. A competitor can rename a module or swap one model family for another.
But if your claim captures a live decision process in functional terms that are still specific, it becomes much harder to avoid. The goal is not to protect a buzzword. The goal is to protect the logic that drives value.
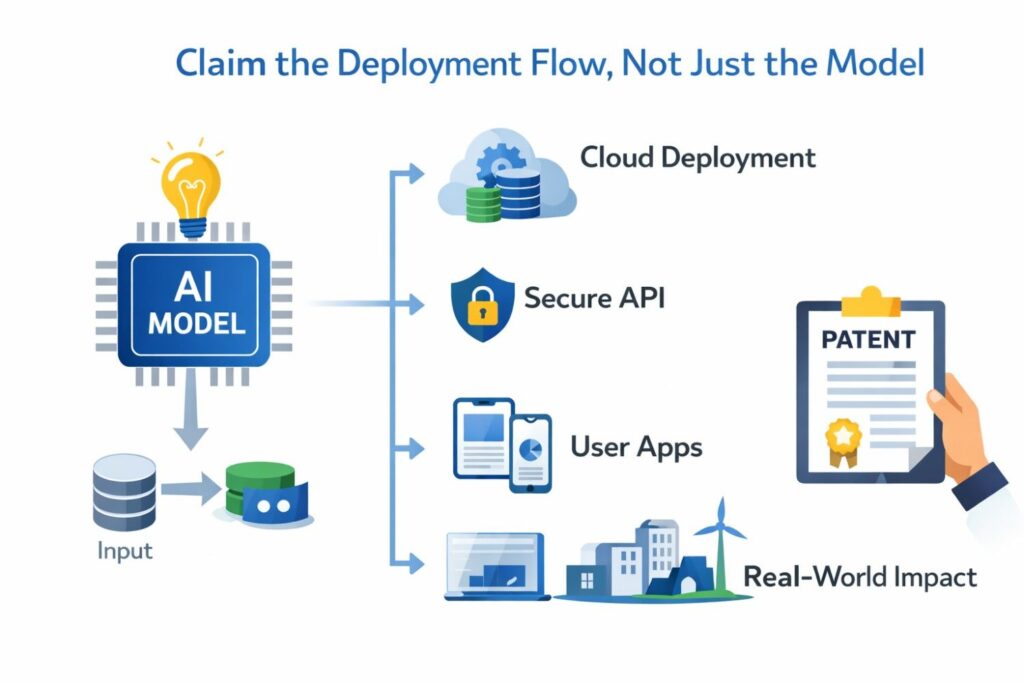
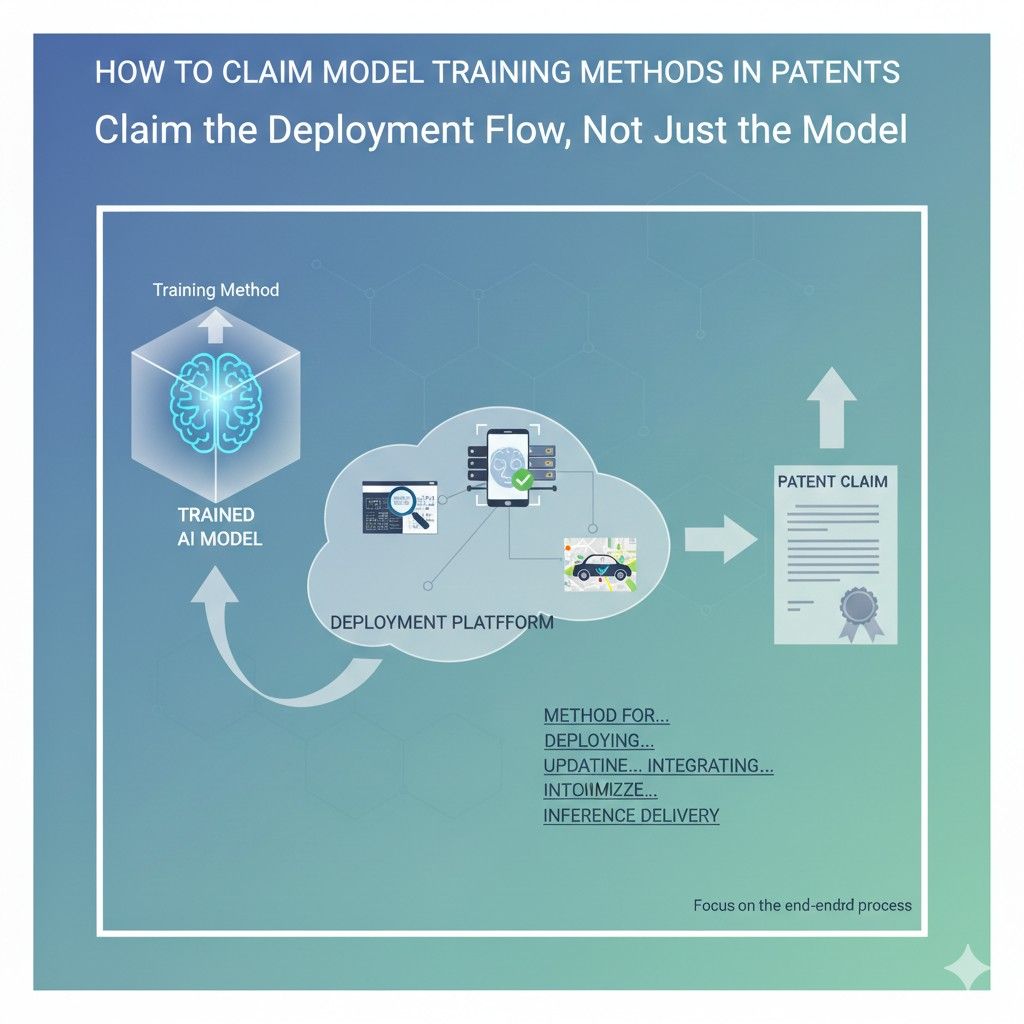
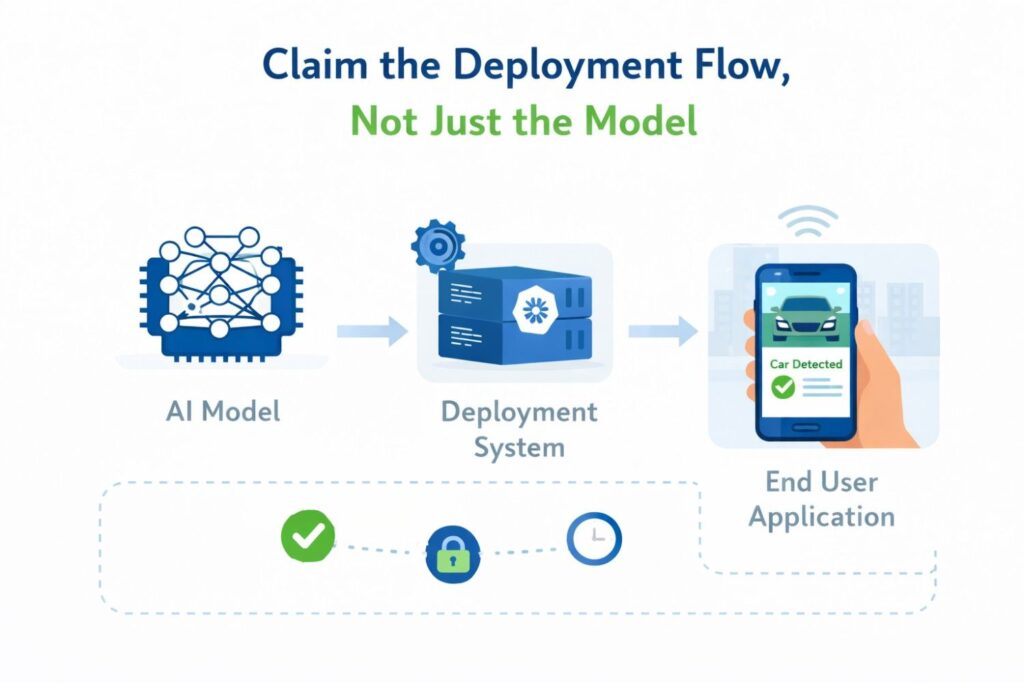
Claim the Deployment Flow, Not Just the Model
A lot of teams make the same mistake when they talk about patent claims for AI. They spend almost all their time on the model and almost no time on the way the model is actually delivered, managed, controlled, and used in production.
That sounds small, but it is often the difference between a thin patent and one that protects real business value. In many products, the model is only one piece.
The deployment flow is where the company turns a technical asset into a stable, useful, revenue-producing system.
If you want stronger protection, you need to look beyond model architecture and ask a harder question. What is special about the way your system runs in the real world?
That is where deployment claims become powerful. They let you protect how requests move through the system, how compute is assigned, how outputs are controlled, how errors are handled, how updates are rolled out, and how the whole thing keeps working under pressure.
That is often the part competitors copy first because it is the part that makes the product usable at scale.
Why deployment is often where the moat gets built
A model can be impressive in a demo and still fail in the market. Businesses do not win because a model exists. They win because the product works day after day for real users, under real load, at a cost that makes sense.
That is what deployment does. It turns intelligence into a dependable service.
This is why claim drafting should not stop at what the model predicts. It should also capture how the prediction is delivered, checked, routed, refreshed, limited, retried, or combined with other system actions.
Those pieces may not sound flashy, but they are often the reason customers trust the product enough to use it in important workflows. If that trust depends on the way you deploy, then deployment is not a side detail. It is part of the invention.
The product customers buy is the deployed system
When a customer signs a contract, they are not buying a set of weights in the abstract. They are buying a working system.
They are buying uptime, response speed, safe outputs, predictable behavior, auditability, integration, and cost control. All of that lives inside deployment.
That matters for patent strategy because your claims should map to what customers are truly paying for. If your company’s edge comes from how the system is served and managed in production, your patent should say so.
A competitor may swap out model internals, but still copy your deployment logic almost step for step. If your claims only protect the model, that competitor may get far too close for comfort.
Model claims alone can leave a large gap
A claim focused only on the model may sound broad, but it can be easier to work around than founders expect.
Someone else can use a different model family, a different training method, or a different tuning approach while still copying the live product experience that made your solution valuable.
That is where deployment claims earn their place. They can cover the flow that sits around the model and makes the full product effective.
That may include the way requests are triaged, the way the system chooses an execution path, the way context is pulled in, the way safety checks are applied before release, or the way outputs are sent to different downstream systems based on confidence or policy.
Those are not just support steps. They may be the core of your market advantage.
Start from the live path, not the technical diagram
A practical way to draft deployment claims is to begin with what happens after a real request enters the system. A user submits a prompt. A machine sends telemetry.
A platform calls an API. A document enters a review flow. What happens next is the story you should examine closely.
This shift matters because technical teams often explain systems as static diagrams. Boxes, arrows, modules, databases, model endpoints. That is useful for architecture review, but not enough for good claims.
Claims become stronger when they describe a live sequence of controlled actions.
What is received, what is checked, what is selected, what is executed, what is stored, what is returned, and under what conditions those choices change. That is deployment as an operational flow, and that is where real protection often lives.
Claim the path requests take through the system
One of the strongest moves in deployment drafting is to focus on request flow.
Many businesses have built a meaningful edge by controlling how different kinds of requests move through their infrastructure. Not every request deserves the same treatment.
Some are simple. Some are costly. Some are risky. Some require extra context. Some must be delayed, denied, or escalated.
If your system distinguishes among those requests in a useful way, that is worth attention. A claim can be built around receiving a request, determining a request trait, selecting one of multiple serving paths based on that trait, and producing an output or action through the selected path.
That sounds simple, but it can be very powerful when tied to real technical behavior and a business result. It protects the operational intelligence of the deployment layer, not just the raw model output.
Deployment logic often controls cost better than the model does
Many founders assume the model is the main source of performance leverage. In reality, the biggest margin gains may come from deployment.
Serving rules, batching logic, caching, staged execution, selective retrieval, dynamic model choice, and fallback behavior can have a huge effect on unit economics.
That is exactly why deployment deserves claim focus. If your company found a way to keep quality high while reducing live inference spend through smart serving logic, that is not just infrastructure tuning.
It may be one of the most important inventions in the stack. A patent that captures that flow can help https://thompsonpatentlaw.com/what-does-a-patent-protect-startups/
behind better margins.
Protect how the system handles scale
A system that works for one hundred users is not the same as a system that works for one million. Scale introduces pressure. Queues grow. Latency becomes visible.
Edge cases multiply. Failures become expensive. The deployment flow that handles this pressure may be where your real advantage sits.
If your platform uses a particular way to distribute load, assign jobs, stage execution, or shift requests across compute resources based on conditions in real time, those choices may deserve claim treatment.
This is especially true when the scaling method preserves output quality or policy compliance while usage grows. That kind of deployment design can be hard won and easy for others to copy once they see the product succeed.
The strongest deployment claims describe controlled change
Deployment is not static. Good systems adapt while running. They switch paths. They defer actions. They retry. They escalate. They swap resources. They update context.
They block release when checks fail. That dynamic control is often where the invention sits.
A useful claim drafting habit is to ask where the system changes behavior in response to conditions. Does it choose a smaller or larger model based on urgency?
Does it suppress output delivery until a structural check passes? Does it route certain requests through a policy layer before any external action is allowed?
Does it trigger a second evaluation only when the first pass falls into an uncertainty band? These kinds of controlled transitions are much harder to design around than generic descriptions of deployed AI.
A model endpoint is not the same thing as a deployment invention
Many teams point to an endpoint and think they have described deployment. They have not.
An endpoint is access. Deployment invention is the logic and structure around execution. It is the method by which the system decides how to process, contain, verify, release, or act on a request.
That distinction matters because claim language should not settle for surface-level system description. Saying a server hosts a model and returns an output usually adds very little.
Saying a system receives a request, determines a processing class, assigns the request to one of multiple execution environments, applies a release condition to the output, and selectively triggers a downstream action based on the release condition is far more meaningful.
That begins to capture what deployment actually does for the business.
Claim how outputs become usable in the real world
A model output by itself is often not enough. Businesses need outputs that can be trusted, consumed, logged, reviewed, structured, or acted upon.
The deployment flow often does the heavy lifting here. It shapes raw output into something operational.
This is where many overlooked inventions live. Your system may transform an output into a machine-readable form before release. It may check the output against a schema.
It may compare it to a policy library. It may attach confidence information and use that to decide whether the output is shown, held, or escalated. These are not minor extras. They may be the exact reason customers can safely use the system inside a serious workflow.
Think about deployment as the bridge between AI and business process
Companies do not deploy models for fun. They deploy them to improve a business process.
That means the most valuable claim language often sits at the bridge between AI execution and business action. What happens after the model runs may matter just as much as what happens inside the model.
Suppose your system does not merely classify a document, but uses the classification to trigger a review path, assign a queue, set a priority level, and control which human sees the result.
That is deployment value. Suppose your system does not merely answer a user question, but determines whether to show the answer directly, ask for clarification, or open a guided workflow based on detected uncertainty.
That is deployment value too. When the model is tied to process control in a specific and useful way, claims should capture that bridge clearly.
Draft around the production problem you solved
Every meaningful deployment system solves a production problem. Maybe requests were too expensive to serve uniformly. Maybe outputs were unsafe to release without filtering.
Maybe latency was too high for live use. Maybe reliability dropped under variable load. Maybe customers needed strict traceability. These are not abstract engineering concerns. They are business blockers.
The best claims often come from naming that blocker and then describing the deployment flow that solves it. This keeps the claim rooted in reality. It also helps avoid vague language.
Instead of speaking in general terms about model serving, you start speaking in concrete terms about how the system addresses a production constraint. That makes the invention easier to explain, easier to defend, and more likely to match what a competitor would try to copy.
H4: What problem made this deployment flow necessary?
This is one of the most useful questions a business can ask when preparing patent material. If the answer is weak, the claim may be weak too. But if the answer is sharp, the path forward usually becomes clearer.
Maybe the flow exists because low-latency users cannot wait for a full multi-step pipeline. Maybe it exists because some requests carry more legal or financial risk than others.
Maybe it exists because a single serving path made the product too expensive to sell. Once you know the production pain that forced the deployment design, you can draft claims that speak directly to the solution rather than drifting into generic AI language.
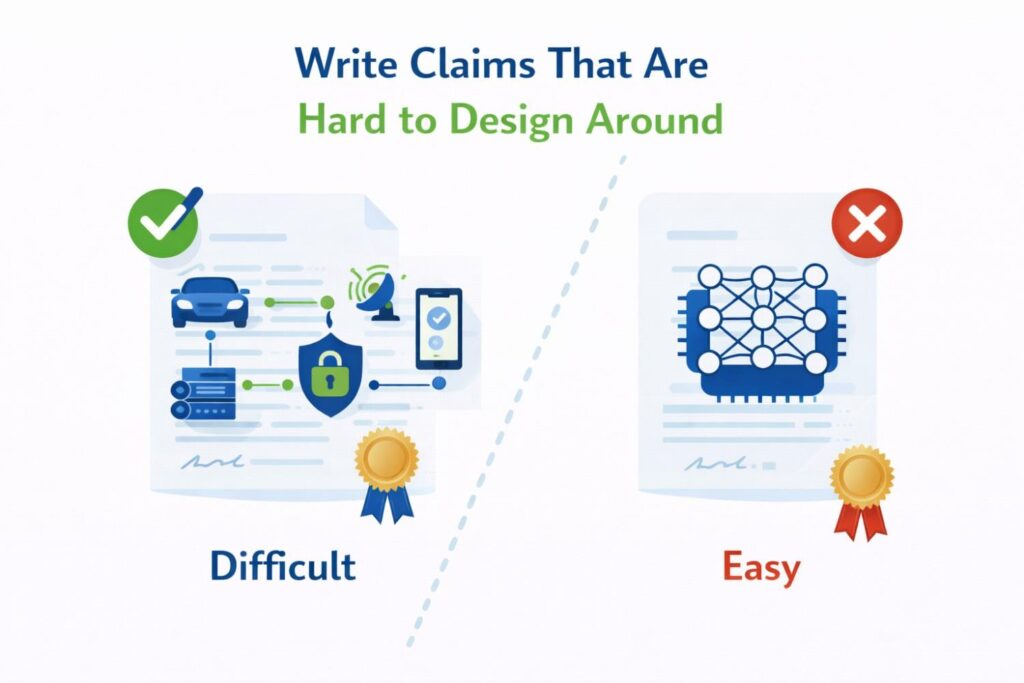
Write Claims That Are Hard to Design Around
A patent can look strong on paper and still fail at the exact moment it matters. That happens when a competitor can copy the business value, change a few technical details, and walk around the claim with very little effort.
This is one of the biggest problems in AI patent drafting. Teams often describe the invention in a way that sounds broad, but is actually narrow in the wrong places.
They lock themselves into one model type, one data format, one serving layout, or one sequence that is easy for others to tweak.
If you want a claim that holds up better in the real world, you need to draft with design-around risk in mind from the start. That means thinking like a builder, a competitor, and a business owner at the same time. You are not just asking what your system does.
You are asking how someone else might try to copy the same result while changing the surface etails. The goal is to protect the real engine of value in a way that still fits the invention, but is not so easy to dodge.
Start with the move a competitor would make first
The easiest way to draft weak claims is to write from your own point of view only. Founders know their product deeply, so they often describe it exactly as built.
That feels natural, but it can create claims that are too tied to the current version. A competitor does not care how you built it. A competitor cares about how to recreate the value without stepping into your words.
That is why this section should begin with the likely copy move. If someone wanted to imitate your product fast, what would they change first? They might swap the model family.
They might use a different retrieval step. They might move a control function from before inference to after inference. They might split one system action into two smaller actions.
When you can see those moves early, you can draft claims that reach the core logic rather than the temporary wrapper around it.
Design-around risk is usually a drafting problem, not a technology problem
Many teams assume a weak patent means the invention was not special enough. Often that is not true. The invention may be quite strong. The problem is that the claims were written around the wrong features.
They focused on details that were easy to swap while missing the mechanism that created the real business result.
This is good news for businesses because it means the answer is not always to invent more. Sometimes the answer is to describe better. When the claims track the actual source of leverage, they become harder to avoid.
The challenge is to identify which details are essential to the edge and which are just one way of implementing it.
The goal is not maximum breadth at any cost
Some teams hear “hard to design around” and think the answer is to make the claim as broad and vague as possible.
That usually backfires. Claims that float too high over the invention can become weak because they stop saying anything meaningful. They may also run into prior art problems or fail to show a concrete technical path.
A stronger approach is controlled breadth. That means you claim the real logic of the invention in a way that covers meaningful variations, while still staying grounded in specific system behavior.
You are not trying to own every AI workflow on earth. You are trying to own the practical move that makes your product work better and that others would likely want to imitate.
Protect the mechanism, not the label
One of the most common drafting mistakes is to rely on technical labels as if those labels create protection. They do not. A label is often just a name for one implementation choice.
If your claim leans too hard on the name of a model type, a system layer, a component, or a known pattern, a competitor may replace the label and keep the value.
The safer move is to describe the mechanism. What does the system decide, change, compare, select, constrain, or trigger? Under what condition does that happen?
What result follows from that action? When the claim is built around that live mechanism, it is much harder to escape with a simple rename or substitution.
Focus on what must stay true across variations
A very useful drafting question is this: if the product changes over time, what part of the logic must still remain true for it to deliver the same advantage? That answer often points toward the best claim center.
Maybe the specific model will change, but the system will still classify incoming tasks and route them to distinct execution paths based on cost and risk.
Maybe the exact verification tool will change, but the system will still apply a release condition before triggering downstream action.
Maybe the current prompt structure will change, but the system will still generate an intermediate structured representation before final output is allowed. Those durable truths are where stronger claims often begin.
Write from the business advantage backward
A claim becomes more strategic when it is tied to the reason the business wins. That reason might be lower cost, higher reliability, safer automation, faster output, better scaling, or stronger control in a sensitive workflow.
Once you know the advantage, you can work backward and find the technical mechanism that makes that advantage happen.
This helps keep your claim anchored to something real. It also helps prevent drift into technical details that do not matter. If a feature does not materially support the business edge, it may not belong at the center of the claim.
But if a piece of system logic is the reason the product is practical to sell, that is exactly the kind of thing a competitor will want to copy.
H4: Ask what the rival can change without losing the result
This is one of the sharpest tests in all of claim drafting. A rival will change whatever it can, as long as the result still works for customers. The question is which parts they can safely swap and which parts they cannot.
If they can replace your named model, your chosen vendor, your file type, your server setup, or your sequence labels and still deliver the same product value, those details probably should not define your claim too narrowly.
But if they cannot avoid classifying requests by a certain property, applying a certain release gate, or selecting among paths based on a measured condition without losing the business result, those steps may be closer to the true core.
H4: Ask what part of the system creates lock-in value
Some inventions matter because they let the product do something no one else can do easily.
Others matter because they let the product fit naturally into the customer’s workflow and become hard to replace. That lock-in value often comes from system behavior, not raw model design.
If your product becomes trusted because of its control flow, approval logic, action gating, or output structure, then those mechanics may be the parts worth protecting most. Competitors may copy those behaviors long before they copy your exact internals. A hard-to-design-around claim sees that early.
Avoid claims that depend on one rigid order unless order is the point
A lot of design-arounds happen through sequence changes. A competitor takes the same basic logic, moves one check earlier, moves one transformation later, or splits a single step into two separate actions.
If your claim depends on one rigid order that is not truly essential, you may have made their job too easy.
That does not mean sequence never matters. Sometimes the order is the invention because one step changes the conditions of the next in a meaningful way.
But when order is not the heart of the novelty, be careful about writing yourself into an unnecessarily narrow path. The claim should reflect the function of the flow, not a fragile script that can be rearranged.
Claim the decision point, not just the surrounding plumbing
What often makes a workflow valuable is not every part of the pipeline. It is one or two key decisions inside it.
Which model is selected. Whether extra context is added. Whether the output is blocked. Whether a second pass is triggered. Whether an action is allowed. Those are the pressure points.
When claims give too much attention to surrounding infrastructure and too little to those decision points, they become easier to work around.
A stronger strategy is to capture the decision in a way that includes the condition, the branching behavior, and the resulting effect on the system. That usually reaches much closer to what the competitor must actually copy.
Use abstraction carefully and on purpose
Abstraction is powerful when done well. It lets you move from one narrow implementation to a broader protection zone. But sloppy abstraction can kill clarity.
The right kind of abstraction preserves the technical logic while removing unnecessary implementation limits.
For example, you may not need to tie a claim to a specific large language model or retrieval engine if the real invention is conditional selection of a first or second inference resource based on a measured property of the incoming request.

That keeps the claim meaningful while making it harder to sidestep with a different branded tool. The point is not to hide detail. The point is to abstract the right detail.
The more your claim mirrors a real workaround path, the stronger it gets
One of the best drafting habits is to try to break your own claim before a competitor does. Ask how someone would preserve the product’s value while avoiding your wording.
Then revise the claim to cover that move if the move still uses your real invention.
This is not about cheating the boundaries of the invention. It is about describing the invention at the right level.
If the same core logic can be implemented through different but equivalent structures, your claims should have a fair shot at reaching those forms. That is how you make them more resilient without drifting into empty language.
Do not hand the competitor obvious substitution options
Some claim language invites easy escape. A claim that depends on one exact data source, one named architecture, one interface format, one deployment venue, or one vendor-specific feature may be simple to avoid.
Competitors love these openings because they can keep the valuable part and swap the rest.
A more careful draft looks for substitution risk everywhere. If a detail is likely to vary across implementations, ask whether it should sit in the core claim or be moved into dependent support.
That way the main claim protects the durable mechanism, while narrower claims still preserve fallback positions around preferred versions.
Think in layers, not one perfect sentence
Hard-to-design-around protection rarely comes from one magic claim. It usually comes from a set of claims that work together. One claim may protect the broad mechanism.
Another may narrow into a useful conditional path. Another may focus on output gating. Another may cover a production setting or system arrangement. Together they make it harder for a rival to find a clean escape route.
That layered structure matters because businesses do not need theoretical perfection. They need practical coverage that makes copying more painful, more uncertain, and more expensive.
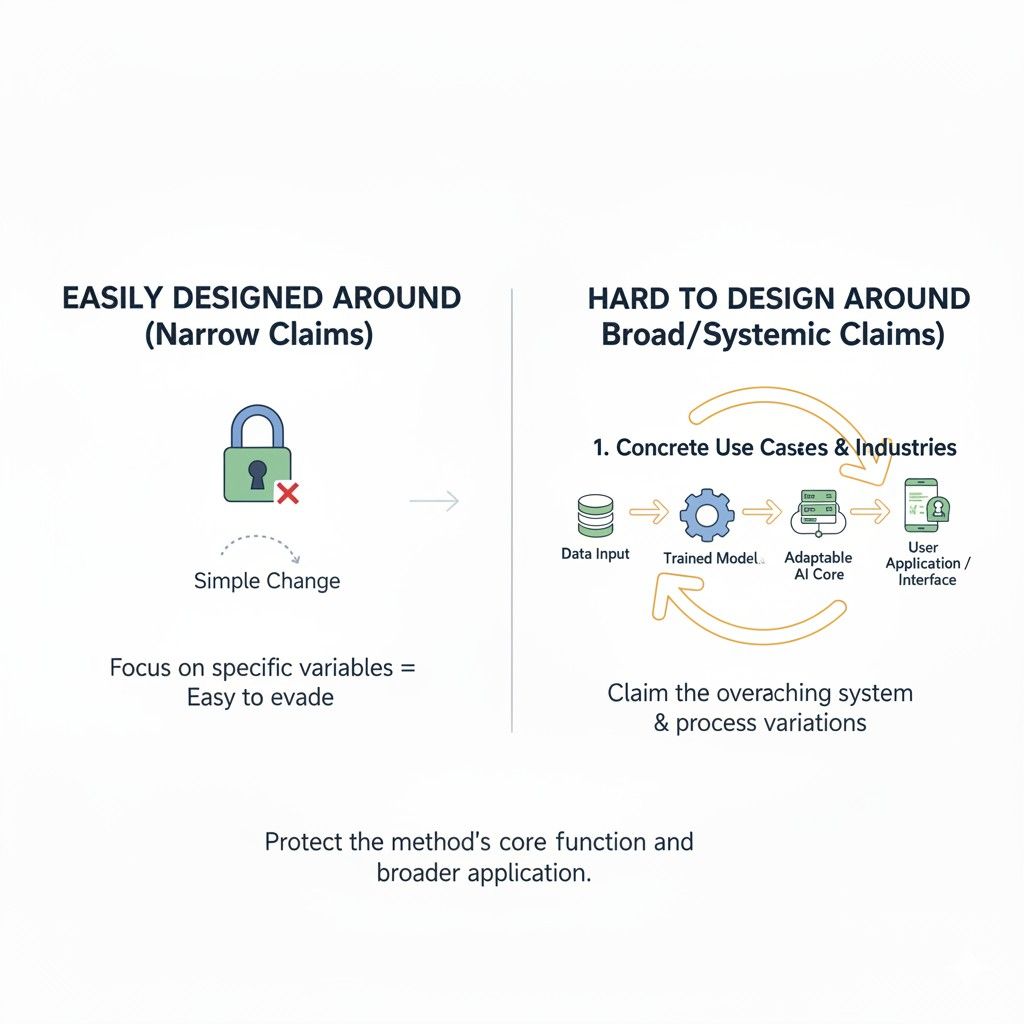
The best patent strategy often creates that effect by surrounding the core invention from several angles.
Wrapping It Up
Drafting claims for inference and deployment is not about using fancy patent language. It is about protecting the real way your product creates value when it is live in the market. That is the big idea running through this whole article.