Most founders building with LLMs know the feeling. The demo works. The product feels smart. Users get excited. Then one hard question shows up. What, exactly, are you protecting?That is where many AI teams get stuck. They know their app is valuable. They know the real work was not just “calling a model.” It was shaping the system around the model so it can find the right data, choose the right next step, use tools at the right time, and return something useful in a way people can trust.
Where the Real Invention Lives in an LLM App
Most teams think the invention is the model. In most cases, it is not. The model is only one part of the product.
The real business value usually comes from the way the full system is designed to solve a hard problem again and again with speed, control, and trust.
That is the key shift founders need to make. If your team is building an LLM app, your edge is often not the base model itself.
Your edge is the way your app finds the right context, handles messy user input, decides what to do next, checks its own work, calls outside systems, and turns raw model output into something a user can rely on.
That is where the invention often lives. That is also where smart patent strategy begins.
The model is not the whole product
Many businesses make the same mistake early. They look at the user-facing prompt or the fact that they are using a powerful model and assume that is the core of the value.
But if another company can swap in a similar model and get close to the same result, then the model itself is probably not where your deepest protection should focus.
The stronger view is to ask what your system does around the model that makes the output better for your customer. Maybe your app pulls live company data before answering a finance question.
Maybe it checks role-based access before showing a result. Maybe it decides whether to call a search tool, a CRM, or an internal workflow engine.
Those system choices are often where the product becomes useful in a way that is hard to copy fast.
The invention is often in the sequence, not the sentence
A lot of founders describe their app with one simple line.
They say something like, “Our AI answers questions about enterprise documents,” or, “Our assistant helps teams complete support work.” That is good marketing language, but it is weak invention language.
The real invention is often in the sequence of operations that makes that result possible.
It may start with classifying the request, then filtering sources, then ranking snippets, then rewriting the query, then picking a tool, then checking whether the tool response is complete, then generating a final answer with a confidence signal. That chain is not fluff. That chain is the work.
For businesses, this matters because the sequence often maps to what customers pay for.
They are not paying for a sentence generator. They are paying for fewer errors, better speed, safer automation, and smoother workflows.
When you describe your product in this more exact way, you begin to see where valuable claim language can come from.
Good protection starts with the business problem
A strong AI patent story does not start with “we use an LLM.” It starts with a business pain that older systems handled badly. That framing helps you avoid broad and empty language.
A useful way to think about it is this: what costly problem did your team reduce in a measurable way? Maybe users used to search across five tools and still miss key information.
Maybe support teams wasted time switching between tickets, internal docs, and billing systems.
Maybe legal teams could not trust answers unless humans checked every line. If your app solves one of those pains through a specific orchestration flow, that is where your invention story gets strong.
This is important for businesses because the clearest claim themes often come from business friction.
When your system reduces missed data, bad routing, wasted clicks, slow handoffs, or wrong tool calls, you have something concrete to anchor to. Concrete stories are easier to defend and easier to explain later to investors, partners, and acquirers.
What users see is only the surface
Users see a chat box, a polished answer, and maybe a few action buttons. That surface can look simple even when the back end is doing something very hard.
Founders should not let the clean user experience hide the technical value that sits below it.
A good internal exercise is to ignore the interface for a moment and map what must happen behind the scenes for one successful output. Ask what had to be fetched, ranked, cleaned, checked, routed, logged, and transformed.
Ask what would break if each part were removed. The steps that cause quality to fall apart are often the steps where the invention lives.
This matters in a business setting because competitors often copy the visible layer first.
They can copy the look, the style, even some of the wording. But it is much harder to copy the system spine if that spine has been deeply thought through and clearly protected.
Retrieval is not just pulling documents
In RAG systems, many teams think retrieval is solved because they use embeddings and a vector database. That is only the start. Raw retrieval is not usually the business edge. Intelligent retrieval is.
The real invention may sit in how the system decides what should be retrieved, when retrieval should happen, how much context should be pulled, which sources should be blocked, how stale data should be handled, and how the app chooses between conflicting pieces of information.
A company that solves these issues well is not just “using RAG.” It is building a retrieval architecture that turns a general model into a useful business product.
For a business, this is where strategic value grows. Better retrieval can reduce wrong answers, lower review cost, improve trust, and shorten time to action. Those are not academic gains.
Those are product and revenue gains. If you can tie your retrieval design to these business outcomes, you get stronger ground for both product messaging and protection planning.
The best systems know when not to answer
One of the clearest signs of a mature LLM app is not that it always answers. It is that it knows when an answer should be delayed, checked, narrowed, or refused. This kind of control is often one of the most valuable parts of the invention.
Maybe your app detects weak source support and asks a follow-up question. Maybe it shifts from free-form generation to a rules-based flow when the task becomes risky.
Maybe it routes the case to a human reviewer if the output touches policy, money, or legal exposure. Those choices are not side features. They are signs that the system is built for real use.
For businesses, this is very actionable. If your team has created logic for confidence thresholds, escalation paths, or guarded tool access, document it. Write down when the system continues on its own and when it stops.
This is often where product trust is won, and trust is often where enterprise value is built.
Agents become valuable when they act with structure
The word “agent” gets used too loosely. Many products call themselves agentic when they are really just running a few prompts in a row.
The more useful business question is whether the system can handle work with memory, planning, tool choice, and error recovery in a way that improves outcomes.
That means the invention may not be “an agent that completes tasks.” It may be a structured framework for selecting goals, generating task plans, choosing tools based on current state, handling failed calls, and deciding when enough work has been completed to return a result. Structure is what turns a flashy demo into a durable business system.
This is important for businesses because structured agents can unlock cost savings only when they are predictable enough to trust.
If your company has built methods that keep agent behavior within useful boundaries, that is a real asset. It should be described clearly and treated like core intellectual property.
Tool use creates a traceable business moat
When an LLM app uses tools, the value often becomes easier to see. The system is no longer just producing text.
It is reading from systems of record, updating databases, running workflows, creating tickets, drafting reports, or triggering downstream actions.
That is where a business moat can become very real. The invention may lie in how the model chooses a tool, how it fills required fields, how it checks permissions, how it validates tool responses, or how it decides between multiple tools that could solve the same need.
These are practical system choices with direct business impact.
A very useful step for founders is to look at each tool call in the product and ask what logic sits around it. What must be true before the call is allowed? What happens when the output is incomplete?
What gets logged for later review? What gets shown to the user before a final action is taken? The answers to these questions often reveal highly protectable design work.
Orchestration is often the hidden asset
Most AI teams spend a lot of energy on prompts, but orchestration is usually the bigger long-term asset. Orchestration is the logic that holds the whole experience together.
It decides how data moves, how tasks split, how components interact, and how quality is controlled across the flow.
This kind of architecture can be easy to overlook because it sits between the obvious pieces. Yet that middle layer is often what makes the difference between a fragile app and a scalable one.
In many companies, the orchestration layer contains the best claim material because it captures how the product behaves under real conditions.
For businesses, orchestration has another benefit. It is easier to align with commercial value.
You can show how your orchestration reduces human review, shortens task time, improves compliance, or raises completion rates. That gives you stronger language not only for patent work, but also for sales, fundraising, and market positioning.
Your edge may live in the exceptions
A weak demo handles the happy path. A serious product handles the messy path. This is where many companies have deeper invention value than they realize.
What happens when retrieved sources conflict with each other? What happens when a tool returns partial data? What happens when the user asks for an action they do not have permission to take?
What happens when the model chooses the wrong format for a downstream system? The logic your team built for these moments is often more valuable than the basic flow itself.
This is highly actionable for any business building AI right now. Spend time documenting exception handling.

Do not just map the ideal path. Capture the fallback path, the retry path, the correction path, and the approval path. In many cases, that is where your most defensible invention sits because that is where real product maturity shows.
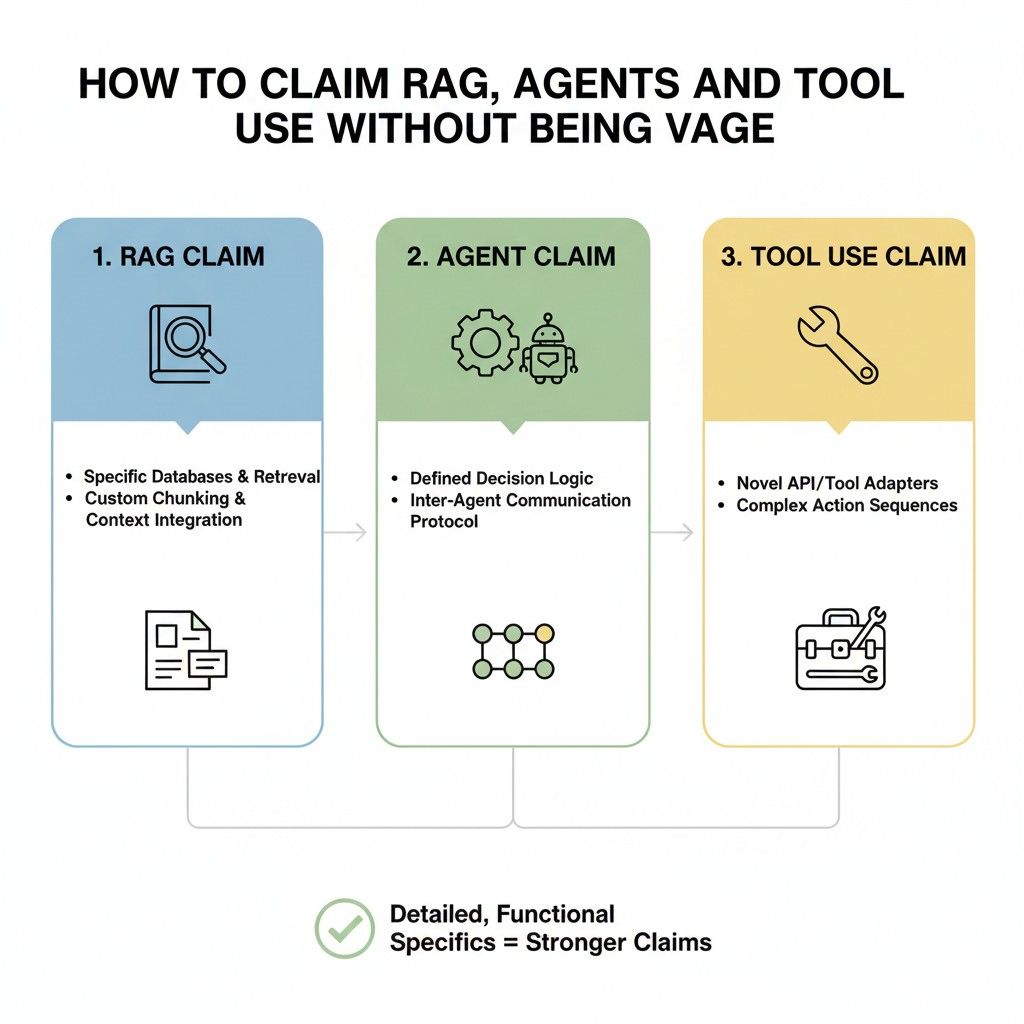
How to Claim RAG, Agents, and Tool Use Without Being Vague
A lot of AI patent writing goes wrong in one simple way. It sounds impressive, but it does not say much.
It uses words like intelligent, dynamic, adaptive, agentic, context-aware, and automated, yet it never explains what the system actually does. That is a problem because vague language does not protect the hard work. It hides it.
If you are building an LLM app, the goal is not to describe your system in the most fancy way. The goal is to describe it in the clearest way. Good claims do not win because they sound advanced.
They win because they capture real system behavior in a way that is broad enough to matter and specific enough to mean something. That is the balance founders need to learn.
Why vagueness hurts more in AI than in other software
AI products already live in a noisy market. Many teams are using the same base models, similar language, and similar product labels. That means your wording has to work harder.
If your claim language is too loose, it starts to sound like every other AI company in the market.
This is where many businesses lose leverage. They say their app uses retrieval to improve outputs, agents to complete tasks, and tools to perform actions. That may be true, but it is still too empty.

A strong claim has to explain how retrieval is done, how the task flow is managed, and how the tools are selected, validated, and used inside a real system.
Otherwise, you are not protecting the advantage. You are only naming it.
A strong claim starts with system behavior
The easiest way to avoid vague language is to shift from describing ideas to describing behavior. Instead of saying the system is smart, say what it does when a user request comes in.
Instead of saying the app is context-aware, say how it chooses the context. Instead of saying the agent can take action, say how it selects, prepares, and executes actions.
This is the most useful mindset for businesses. Ask what the system actually does step by step when it works well. Those steps are where the meaningful material sits.
Strong claims often come from behavior that repeats across real customer use cases. When that behavior improves reliability, speed, safety, or accuracy, it becomes even more valuable.
RAG is not a claim, it is a category
Saying your app uses retrieval-augmented generation does not tell anyone what is inventive about the system. RAG is just a broad label. It is like saying your app uses a database. That may be true, but it is not enough.
The real work is usually in the details around retrieval. How is the query interpreted before retrieval starts? How does the system decide which data source to search first?
How are chunks filtered before they go into the prompt? How does the app handle stale content, duplicate content, conflicting content, or user-specific access rules?
Those design choices are where the claimable material often lives.
Claim the retrieval logic, not just the retrieval label
The most useful way to think about RAG claims is to focus on the retrieval logic that changes the outcome.
That means the mechanism that improves what gets pulled, what gets excluded, what gets ranked higher, and what gets passed forward into generation.
For a business, this is highly practical. Look at the parts of retrieval that directly affect customer trust.

If your product does not simply fetch nearby chunks but instead filters based on role, workflow state, document freshness, prior user actions, or source reliability, that is the kind of detail that matters. That is where broad marketing language should turn into precise invention language.
Claim what happens before retrieval
Many strong systems do important work before any search happens. They rewrite the user query, classify the request type, identify the domain, predict the likely answer shape, or narrow the scope based on the user account or task state.
That matters because the retrieval result is often only as good as the setup. If your system improves retrieval by shaping the request before search begins, that preparation may be one of the strongest parts of the invention.
Businesses should not overlook this layer just because it happens quietly in the background.
Claim what happens after retrieval
A lot of weak AI writing ends the technical story too early. It says the system retrieves context and then generates a response. But in most strong products, there is a lot of valuable logic between those two points.
Maybe the app scores the returned passages, removes overlap, checks consistency across sources, adds metadata, applies a trust threshold, or restructures context into a format the model handles better. Those are not minor details.
In many cases, they are the reason the product works in the real world. If your team built this layer, it should not be hidden under the single word retrieval.
Agents need structure, not hype
The word agent has become so overused that it often says very little by itself. In product language, almost anything can be called an agent. In a patent context, that is dangerous because it creates fog where there should be structure.
The right move is to stop calling the invention an agent and start explaining the operating pattern. What goal does the system receive? How does it break the work apart?
How does it choose between next steps? How does it track progress? How does it recover from failure? How does it know when to stop?
Those are the details that make agent behavior real. Businesses should care because this is usually where their product is hardest to copy.
A loose description of an agent may sound modern, but a structured description of task planning and control logic is far more useful.
Claim the decision flow inside the agent
A strong agent claim often comes from the decision flow, not the final task result. The key question is not whether the system can complete a task. The key question is how it decides what to do next while completing it.
That can include choosing whether to ask a clarifying question, whether to retrieve more data, whether to call a tool, whether to retry a failed operation, or whether to escalate to a person.
If your product has a defined way of making those choices, that is a real mechanism. Mechanisms are far more protectable than labels.
Claim bounded autonomy, not unlimited autonomy
Many founders think they should describe agents as broadly as possible. They say the system can autonomously perform tasks across environments. That sounds ambitious, but it is often too loose to be useful.
The better approach is to show how autonomy is bounded in a productive way. Maybe the agent can act only after checking permissions. Maybe it can call only a subset of tools based on user role.
Maybe it must confirm high-risk actions. Maybe it must stay inside a task template for certain workflows. These limits are not weaknesses. They often show where the real product maturity sits.

For businesses, this is important because enterprise value usually comes from controlled automation, not wild automation.
A system that acts within clear boundaries is easier to trust, easier to sell, and often easier to defend as a real invention.
Claim memory with purpose
Memory is another place where vague language appears fast. Teams say the agent uses memory to improve performance. That may be true, but it is still not enough.
You need to explain what is stored, when it is stored, how it is retrieved, and how it changes later actions. Maybe the system stores prior task outcomes and uses them to rank next-step options.
Maybe it keeps user preferences that shape tool selection. Maybe it tracks unresolved subtasks across sessions. Memory becomes meaningful when it changes future system behavior in a defined way.
Tool use becomes strong when it is framed as controlled execution
Tool use is one of the best places to avoid vagueness because it naturally ties the LLM to real-world operations.
The model is no longer just producing words. It is interacting with systems, records, workflows, and actions that matter to the business.
That said, weak descriptions still show up here. A common example is saying the system selects and calls one or more tools to complete a task. That is true, but it does not explain the invention.
The interesting part is how the system chooses the tool, prepares the input, validates the output, handles failure, and decides what to do next.
Claim the selection process for tools
If your system chooses among several tools, there is often a valuable mechanism behind that choice.
It may look at task type, user role, available data, prior failures, required output format, timing, cost, or system state. Those signals are important because they turn tool use into controlled orchestration.
Businesses should study this closely. Tool selection is often where practical product intelligence lives.
If your app does more than map a prompt to a function and instead weighs multiple signals to decide the best next action, that is worth capturing with care.
Claim parameter preparation, not just tool invocation
One of the most overlooked areas in LLM apps is parameter construction. The hard part is often not deciding to use a tool. The hard part is producing the right structured input so the tool call succeeds.
If your system extracts fields from the user request, fills missing values from account state, checks format rules, resolves ambiguity, or transforms raw language into executable parameters, that is not a side issue.
It is often the bridge between language and action. That bridge can be very valuable.
From a business view, this matters because failed tool calls create user frustration, wasted cost, and broken trust. If your product solves that through a specific parameter-building flow, it has real commercial value and real claim value.
Claim verification after tool results come back
Many systems fail after the tool call, not before it. The tool may return partial output, conflicting output, empty output, or output that needs reshaping before the user can benefit from it.
If your app handles that well, the post-tool layer may be one of your strongest assets.
A precise claim can focus on how the system evaluates returned data, checks completeness, compares it against the request, and then either continues, retries, reformats, or asks for human review.
That is much stronger than vaguely saying the system processes tool outputs.
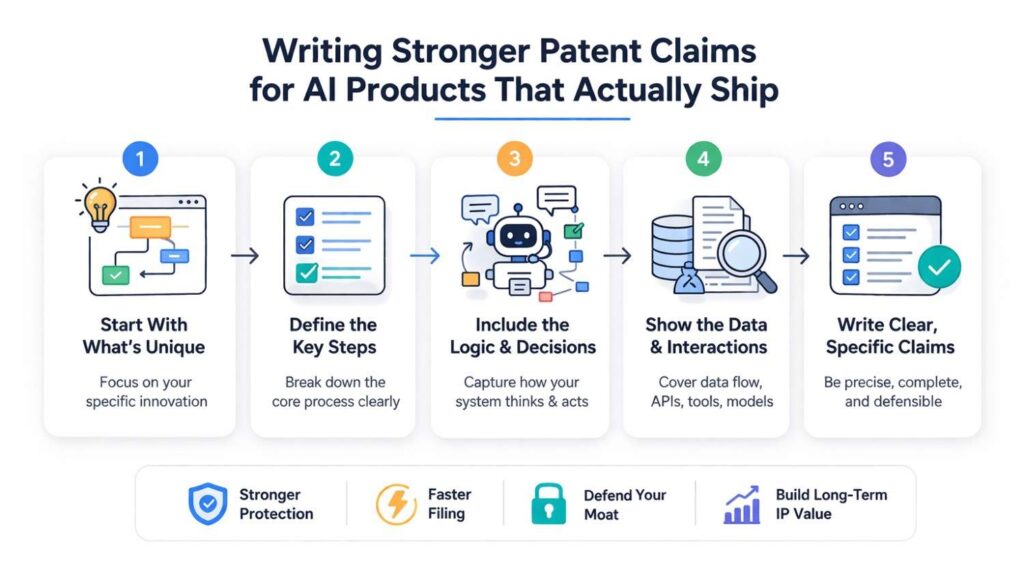
Writing Stronger Patent Claims for AI Products That Actually Ship
A lot of patent writing for AI products breaks for one simple reason. It is written for a theory, not for a product that people actually use. It talks about models in a broad way.
It leans on abstract language. It sounds polished, but it does not track how the system creates value in the real world.
That is a problem for startups and serious product teams. If your company is shipping an AI product, the strongest claim strategy usually comes from the parts of the system that survive contact with real users, messy inputs, changing data, edge cases, and business pressure.
In other words, the strongest claims often come from the product you actually had to build to make the thing work.
Shipping changes what matters
A lab demo and a shipping product are not the same thing. A demo can look great in a short clip.
A shipping product has to work on Monday morning with real customers, incomplete data, security limits, system failures, and people who do not phrase requests in neat ways.
That difference matters a lot when thinking about patent claims. Once a product ships, the value usually moves away from the model alone and into the system around it.
The real invention often sits in the logic that helps the app stay useful under normal business pressure. That is why teams that ship often have better claim material than they realize. They were forced to solve the hard parts.
Strong claims grow out of product reality
The best patent claims for AI products often come from real constraints. They come from the fixes, controls, checks, routing rules, and data-handling methods that had to be added because the first version was not good enough.
This is a very healthy way for businesses to think. Do not ask only what your system does in perfect conditions. Ask what had to be added so that customers could trust it enough to pay for it.
That is where your strongest claim themes often live. The product itself already told you what matters. You just need to listen carefully.
What actually ships is usually narrower and stronger
Founders often worry that narrower claims sound weaker. In practice, the opposite can be true. A claim tied to real shipping behavior is often much stronger than a broad claim built on vague ambition.
That is because real shipping behavior usually reflects actual problem solving. It shows that the team built a repeatable way to handle a business challenge.
It is not just saying, “We use AI to help users do a task.” It is showing how the system turns raw requests into reliable outcomes inside a real product environment. That kind of specificity creates strength.
A shipping product has decision points everywhere
One of the clearest signs that a team has valuable patent material is the presence of decision points across the system. A mature AI product is full of them.
It decides whether retrieval is needed. It decides which source is safe to use. It decides whether a tool can be called. It decides whether output is complete enough to return. It decides whether a person needs to step in.
These decision points matter because they reflect system intelligence in an applied form.
They are not marketing words. They are operational rules. In many cases, they are the exact reason a product works well enough to keep customers.
Good claims reflect how the product behaves under pressure
The strongest AI claims are rarely built only from the happy path. They are often built from how the product behaves when something is unclear, risky, incomplete, stale, conflicting, or broken.
That is what makes them useful for real businesses. A customer does not pay you because your app handled a clean example. They pay you because the app worked when conditions were normal, messy, and annoying.

If your system has logic for retries, fallbacks, confidence gating, role-aware restrictions, cross-checking, or escalation, that is the kind of substance that often leads to stronger claims.
The phrase “actually ship” should shape your whole mindset
When you think about claims for AI products that actually ship, you should stop looking for the most futuristic version of your invention. You should start looking for the most commercially meaningful version of your invention.
That means your patent story should mirror the product story that makes the business work.
It should capture the parts of the system that affect cost, trust, speed, safety, user retention, completion rate, or human review burden. Those are the things that survive in the market. They are also the things competitors will try to copy.
Start with the workflow customers rely on
A useful way to draft stronger claims is to start with one workflow that customers depend on, not with the entire platform. This keeps the effort grounded and prevents the writing from floating into generic AI language.
Pick a workflow where the AI is doing something important. Maybe it helps review technical documents, route support issues, create structured outputs, pull answers from internal systems, or trigger downstream actions.
Then study how that flow works from the first input to the final output. Look for the points where your system made the workflow commercially viable. Those are often the points that deserve the most attention.
A workflow is easier to defend than a vague platform story
A lot of teams describe their platform at a very high level because they think that sounds broad and strategic. But platform-level language can become too loose too quickly.
A workflow-based description is often much stronger because it reveals how the invention behaves in a business context.

When you write from a workflow, you naturally include concrete signals, data movement, control points, and result checks. This creates a better foundation for claims because it ties the invention to real operations instead of abstract identity.
Workflows expose what is truly essential
A good workflow review also helps your team separate core invention from side detail.
Some parts of the product are nice, but not essential. Other parts carry the whole value of the experience. When you trace a workflow carefully, the important mechanics become easier to see.
That is very useful for a business because not every technical feature deserves the same level of protection focus. Your strongest claims should usually track the mechanisms that move the workflow from weak to trusted.
Strong claims often live in the middle of the system
Many founders look first at the input or the output. They ask what the user typed or what the model returned. But the strongest patent material often sits in the middle.
That middle layer is where the product interprets the request, chooses the path, shapes the context, limits actions, validates results, and adapts to system conditions.
In simple terms, it is where the app thinks operationally. That layer is often what turns a generic model into a useful product.
The middle layer is where your business logic meets AI logic
This is one reason the middle of the system matters so much. It is often the place where customer needs, company rules, and model behavior all meet each other.
When your team builds a method for handling that intersection, it is doing real product invention.
For example, the product may combine task classification, user permission data, retrieval settings, and tool availability into a single decision flow. That is not just software plumbing. That can be the heart of a commercially important AI system.
Claims should track what makes the product trustworthy
Trust is one of the hardest things to win in AI. A product does not become trusted because it sounds fluent. It becomes trusted because it behaves in a way users and buyers can rely on.
That means claim strategy should pay close attention to trust-building mechanics.
This includes how the system chooses sources, how it blocks unsafe actions, how it checks output quality, how it handles uncertain cases, and how it logs or explains what happened. These are not extra features. In many shipping products, they are what make adoption possible.
Enterprise trust usually comes from control, not from model size
This matters especially for startups selling into serious businesses. Buyers often care less about the raw power of the model than about whether the system can stay inside business rules.
If your app has built-in methods for enforcing those rules, that work may deserve central placement in your patent story.
This is one of the biggest mistakes teams make. They focus on the model because it feels advanced, while the buyer is valuing the control layer that keeps the product safe and useful. Your claims should reflect where the business value really sits.
Wrapping It Up
At the end of the day, stronger patent claims for AI products do not come from trying to sound bigger than the product. They come from seeing the product clearly. If your team ships something that people use in the real world, then the hard part is usually not the model itself. The hard part is the system you built around it so it can work with speed, control, trust, and repeatable quality.